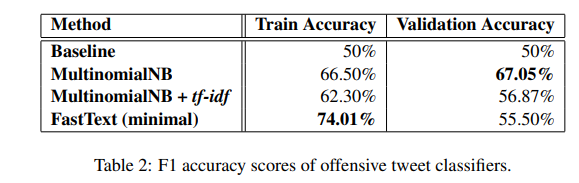
Abstact - Classifying online social media text is more challenging than dealing with normal corpus data due to the use of informal language and non-textual characters. Here we try to analyze different approaches of online tweet classification into offensive and non-offensive categories. We try to enhance the tokenization process to capture better sparsity in our non-textual data. We first attempt to classify tweets using a simple Naive Bayes text classifier. After this, we also try out other advanced text classification approaches on the same data with the aim to get better results. We here try to present a case-study comparing some of such methodologies by analyzing theirpredictions and results.
This project was completed as part of the High Level Computer Vision course offered by Saarland University and instructed by Prof. Dietrich Klakow.